Final Results
Algorithmic Fairness in Clustering: A Study in Replication
Advisor: Layla Oesper
Background
Clustering algorithms take in a collection of data (with no labels) and are able to identify groupings of items in the data that share similar features. Numerous clustering algorithms exist. But one popular such algorithm is the k-means clustering algorithm (along with related algorithms k-medians and k-medoids). This algorithm aims to minimize the total variance amongst items clustering together, for a provided number of clusters. This approach has been used in a number of different domains including document clustering, identifying regions of cities with higher crime rates, or identifying cancer patients with different molecular profiles. However, in recent years there has been in increased focus on whether such clustering can be considered “fair” when considering certain subgroups in the data (e.g., demographic groups).
A number of modifications to the k-means (and related clustering algorithms) have been proposed in recent years to ensure that their output is “fair”. For example, Ghadiri et al. recently proposed a modification to the k-means objective function that changes how cluster centers are chosen. Alternatively, Chierichetti et al. introduced the concept of a fairlet - a minimal set of data items that satisfy fair representation while approximately preserving the clustering objective. However, there are many challenges associated with such approaches. For example, how do they affect the computational complexity of the clustering algorithm and what types of fairness do they work with?
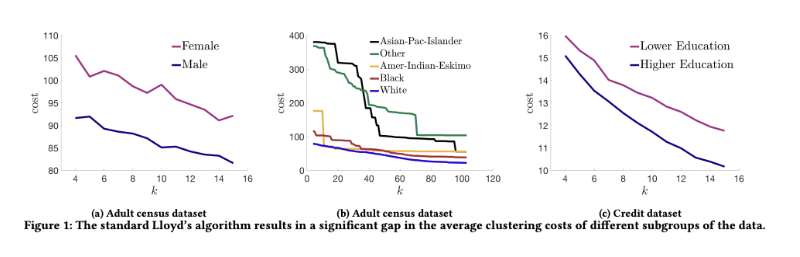
The project
In this project you will investigate approaches to incorporating fairness into the k-means algorithm (and related clustering algorithms). In particular you will:
- Will understand how the k-means clustering algorithm (and related algorithms) work. This will include studying common variations of the k-means algorithm such as Lloyd’s , k-means++ or Hartigon-Wong.
- Study what it means for a clustering algorithm to be “fair”.
- Read and understand recent literature on modifications to the k-means algorithm that ensure more “fair” output.
- Study in depth and reproduce the results (both theoretical and empirical) from a recent publication that introduces a method for fair k-means clustering. You will also understand the strengths and weaknesses of the approach you study.i
Recommended experience
Courses that could be useful for this project include Algorithms, Machine Learning and Making Decisions with AI. Some readings may assume basic knowledge of derivatives from Calculus as well.
References/inspiration
Below are a few papers containing information about fairness in clustering. These are only intended to provide you a minimal start for your literature search - they are certainly not the only nor necessarily the best sources for ideas. You will be finding and reading many additional papers!
- Chierichetti et al., “Fair Clustering through Fairlets.” Advances in neural information processing systems, 2017.
- Ghadiri et al., “Socially Fair k-means Clustering.” Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. 2021.
Meeting Time(s):
Fall Term, MWF 5A