Results
Results
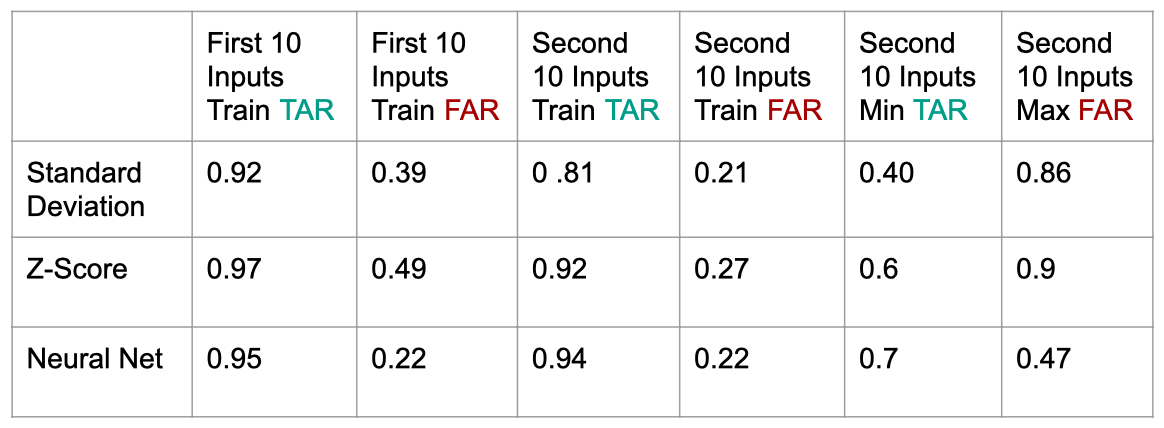
Table 1: TAR and FAR when Testing Models
While the standard deviation based models had difficulty when training on the first 10 inputs compared to the second 10, the neural network model performed similarly well when using both the first and second 10 inputs as training. It also performed better on the worst users, who likely had the least consistent keystroke dynamics. While there are many possible explanations for this, one reasonable explanation is because the neural network model was able to wholistically look at the input password and pick up on patterns spanning many keystrokes while the statistical models looked at each keystroke individually without the context of surrounding keystrokes.
One clear drawback to the neural network compared to the statistical models was the time it took to create the model for each user. The neural network approach took about 5 minutes per user to retrain a model, connecting the template model to the binary classification layer, while the statistical models took about 8 milliseconds per user to calculate the mean and standard deviation from the 10 samples.
Conclusions
class="margin-bottom-0 text-size-16"
Based on our results, keystroke recognition is a promising addition to traditional character passwords in some contexts. Though there are clear limitations to keystroke identification, our relatively high true accept rate with preliminary models shows that keystrokes can consistently be used to identify most users.
We explored this using dimension reduction to visualize each user’s separability from others (Figure 1). Here we have a t-SNE plot which has mapped the users’ high dimensional data down to 2 dimensions while preserving the local structure of the data. Each point is a single password attempt, colored based on the user. We can see that many users’ inputs form clusters and should be distinguishable from others’. However, this clear clustering is not universal to all users.
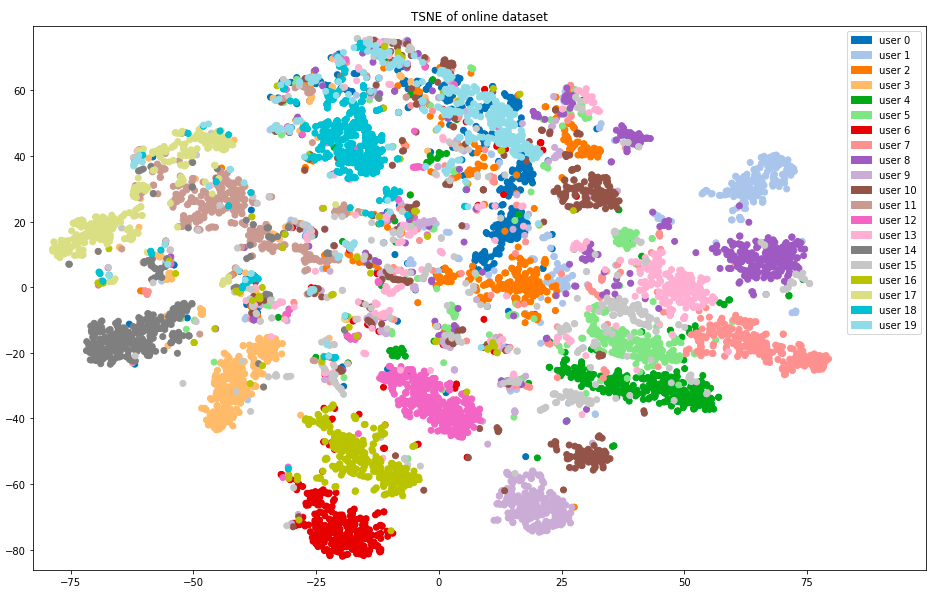
Figure 1: t-SNE Dimension Reduction of 20 Users from Online Data Set
Pulling out two of the users shows some users having much more consistent keystrokes than others (Figre 2). This would likely result in any model performing much better on the left user and worse on the right.

Figure 2: t-SNE Dimension Reduction of 2 Individual Users from Online Data Set