Neural Network Model
Key Objectives
The key objectives we wanted to fulfill when designing a neural network approach to identifying users were:
1. We did not want to train a new model for each user. This would require storing a unique model for each user, taking up a lot of storage potentially leading to very long run times for each new user account.
2. The model must be stored in a way that makes it challenging for attackers to extract
biometric data. This means that we would need to store the data in a way that couldn't be
reverse engineered into keystrokes. Specifically, this would also mean we cannot
permanently store the user’s 10 training inputs.
3. The model must consider passwords of different lengths. This would be important if the model were deployed outside of a test environment.
Method
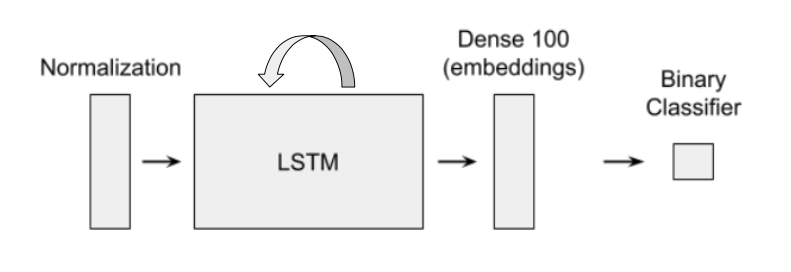
Figure 1: Structure of Binary Classification Neural Network for Regocnizing Individuals Based on Keystroke Dynamics
To address these problems, we aimed to build a model as outlined above. The neural network is made up of a normalization layer, a long short-term memory (LSTM) layer, a hidden dense layer with 100 nodes, and a binary classification layer. As we will discuss later, we are able to swap out the output layer for different users. The LSTM layer is a gated recurrent unit, which will accommodate inputs of any length to the model. This is done by looping the layer’s output back into the LSTM and updating it for each unit of input. The dense layer will contain high level features or embeddings of a user’s keystroke dynamics. These embeddings are low dimensional vector representations of the inputs which, ideally, place similar inputs close together in the embedding space. We should also note that between each layer is a dropout of 0.3 for increased model generalization during training.
Keystrokes are input to the model sequentially as vectors, with each vector containing the dwell time of key n and the flight time between keys n and n+1. Since each input must be a hold time flight time pair, we drop the last keystroke from the input because this key does not have a flight time to a subsequent key.
Our method first trains the model to recognize different users entirely within a subset of the online data set. With the model trained to differentiate between those users, we assume the model identifies important, generalizable features of a user’s keystrokes in the embeddings layer. We then use transfer learning to apply the model to new users.
This is done by freezing the model from the input layer to the embeddings layer and dropping the original output classification layer.
For each new user, we replace the old output layer with a binary classification layer to determine whether a set of inputs should be accepted or rejected. We then retrain the template model to connect the frozen layers to the binary classification layer. This is done using the original training data as false inputs and 10 training inputs from the true user as true inputs. We upsample the 10 true training inputs to match the number of false training inputs. After this retraining step, we are able to begin accepting or rejecting new password attempts.
With this method of connecting a template model to a binary classification layer, we avoid having to store an entirely new model for each user and instead only have to store the weights from the template to the output to recreate the model for each user.
With this method of model creation established, we must find an optimal threshold for the binary classification layer to get as close to the Equal Error Rate as possible. This is done using leave one out cross validation tests with only the training data. For each user in the online data set, we perform the method described before with ⅔ of users as training and ⅓ as testing. The TARs and FARs at different thresholds are then averaged across users. We achieved the Equal Error rate on just the training data at a threshold of about 0.045 with about 70% TAR and 30% FAR. With the optimal threshold found using only the online data set, we tested the threshold on newly retrained models using the survey data set.