Theory
The BVAE (short for Bimodal Variational AutoEncoder) is a neural network comprised of two variational autoencoders with a shared latent space.
It's design is largely derived from A Neural Framework for Retrieval and Summarization of Source Code by Qingying Chen and Minghui Zhou, which can be read here
An Examination of the Task at Hand
The BVAE attempts to perform well at two tasks, code retrieval and code summarization. At the outset, those might seem like two somewhat unrelated tasks; however, at further consideration we can see how intuitively these tasks are two sides of the same coin. Summarization attempts to take code and somehow transform it into a small segment of natural language, while Retrieval attempts to take a small segment of natural and rate/retrieve a code snippet based on that.
Thus, we reach the BVAE. To give a high-level overview, the BVAE attempts to learn to create a common encoding (the "latent representation") for source code and corresponding natural language strings, such that a code snippet should have a very similar latent representation to natural language which corresponds to it and vice versa.
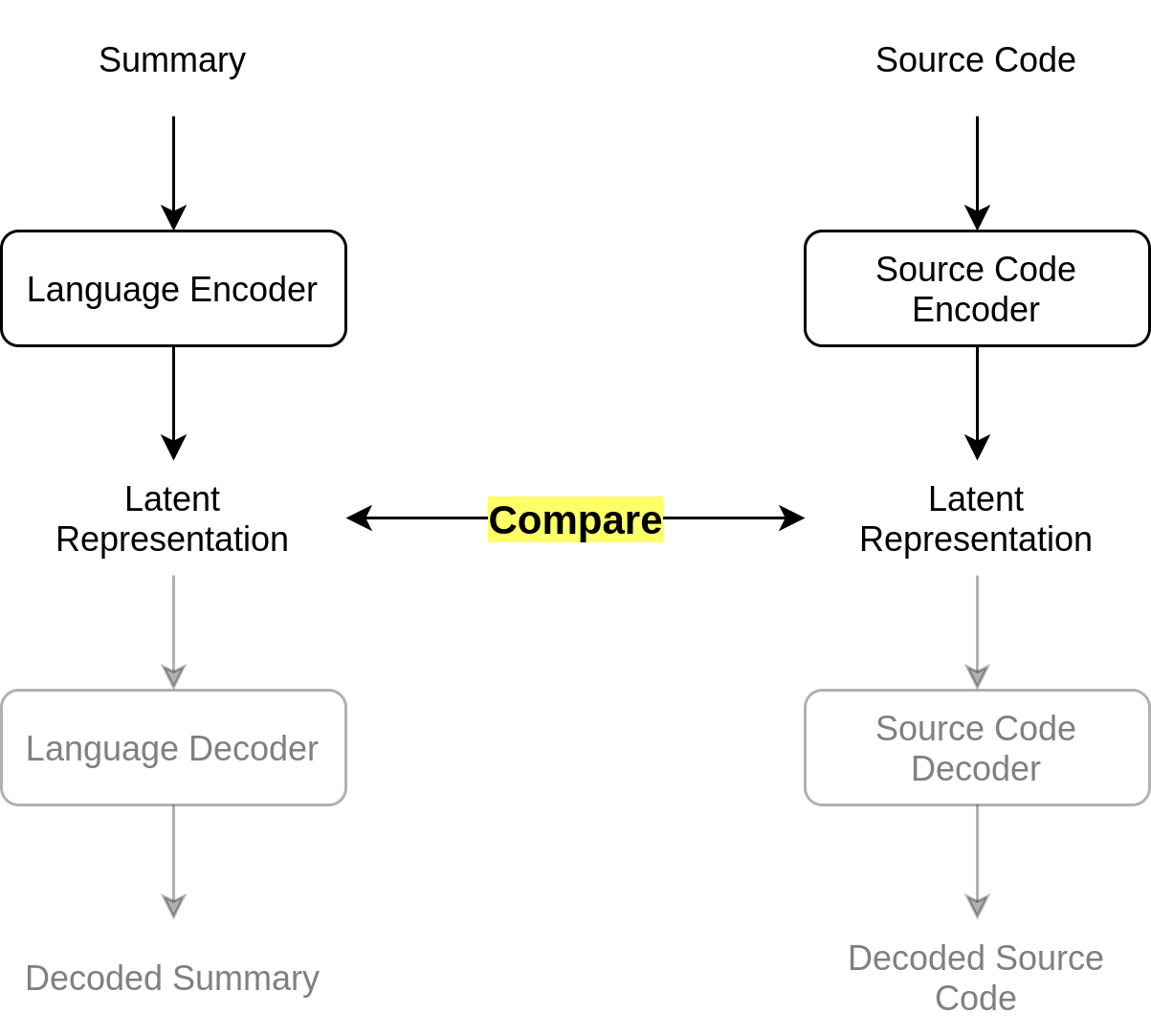
In order to properly learn this latent representation the BVAE needs an encoder and a decoder for source code and a similar pair for natural language. This results in two semi-distinct neural networks which use KL-divergence loss to keep their latent representations similar, as pictured below.
A Note on Baselines
Though the details concerning our baselines are covered in the implementation section, here's a brief overview of the idea behind their designs:
RET-IR turns the query, as well as all natural language summaries in the database, into vectors using a special scoring method for each word in the string. Once all natural language segments are represented as vectors, they can be compared via Cosine Similarity, a common comparison metric for vectors, giving us our ordered ranking.
IR uses common alignment techniques, namely Levenshtein Distance (commonly known as Edit Distance), to compare the code segment to all summaries in the dataset, finding and retrieving the closest one to use as the summary.

This diagram lays out the basics of the BVAE's structure. As discussed, two encoder-decoder pairs each make up their own neural network, the two only being tied together once we introduce KL Divergence Loss. For now, this basic structure shows both summaries and snippets being encoded to and decoded from a latent representation. Below, we show how specific tasks are performed.

Now, all neural net models need loss in order to learn, and this particular model uses two kinds of loss. Loss is herein calculated both through comparison of decoded summaries/code snippets to their original versions that were encoded (Reconstruction Loss) as well as comparison of the latent representations of encoded code/summary pairs (KL Divergence Loss). Through inclusion of both of these loss metrics, the model can sufficiently learn encoding methods that can correctly decode into either input format. Again, technical details on this functionality are given in the implementation section.
Retrieval is performed fairly simply once the model is set up: First, encode the entered query into its latent representation. Then compare that latent representation to the latent representations of all code snippets in your database, and find and return the code corresponding to the most similar one.

Summarization is even more straightforward: Encode the entered code snippet to its latent representation, then decode that latent representation as natural language. On the implementation end this will become a good bit more complicated, but from an abstract view this task is relatively simple.