Want to use our code? Look at this first!
This page gives a high-level overview of our code structure and some info about using it.
Code structure
The diagram below shows the folders in the code dump from the Downloads page, relating them to the major components described in the SMT Intro page, and showing the major classes in each of them. Solid arrows indicate subclassing/interface implementation, dashed arrows indicate that one class is heavily used by another, and the color of the outlines indicates which components of the project use which other components.
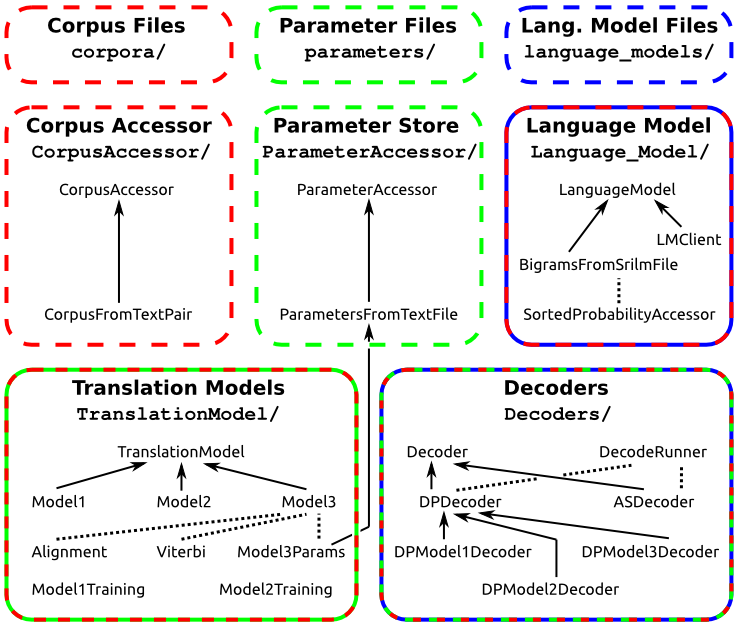
Class descriptions
Below are brief descriptions of what role is played by each class in the diagram above. Look to the source files for more detailed documentation.
Corpus Accessor
- CorpusAccessor: describes an interface for accessing bilingual corpus data.
- CorpusFromTextPair: provides access to bilingual corpora stored as a pair of one-sentence-per-line text files.
Parameter Store
- ParameterAccessor: describes an interface for setting/getting and importing/exporting translation-model parameters.
- ParametersFromTextFile: stores parameters and implements import/export from/to a human-readable file.
Language Model
- LanguageModel: describes an interface for obtaining n-gram probabilities.
- LMClient: wrapper for sending n-gram queries to an already-running SRILM n-gram server.
- BigramsFromSrilmFile: allows unigram and bi-gram queries based on the n-gram file exported by SRILM, and constructs SortedProbabilityAccessor objects.
- SortedProbabilityAccessor: allows for efficient access of conditional probabilities such as bi-gram probabilities indexed by one of the two inputs to the probability function.
Translation Models
- TranslationModel: describes an interface for initializing and performing iterations of training on IBM-model parameters (in a ParameterAccessor) on the basis of a corpus (in a CorpusAccessor).
- Model1: implements Model 1 training.
- Model2: implements Model 2 training.
- Model3: implements Model 3 training.
- Alignment: stores Model 3 translation model alignments and computes their associated probabilities.
- Viterbi: implements alignment-manipulation tools used by Model 3 training and alternating-search decoding.
- Model3Params: implements extensions to the functionality of ParameterAccessor needed by Model 3 training.
- Model1Training: provides a command-line interface to Model 1 training.
- Model2Training: provides a command-line interface to incrementally training Model 2 from Model 1.
Decoders
- Decoder: describes a common interface for decoding of an input sentence.
- DecodeRunner: provides a single command-line program for running various combinations of decoder, translation model, and language pair.
- ASDecoder: implements alternating-search decoding using the tools provided by Alignment and Viterbi.
- DPDecoder: implements the core functionality of dynamic-programming decoding.
- DPModel1Decoder: customizes the dynamic-programming decoder for Model 1 decoding.
- DPModel2Decoder: customizes the dynamic-programming decoder for Model 2 decoding.
- DPModel3Decoder: customizes the dynamic-programming decoder for Model 3 decoding.
Using the code
The code dump includes a makefile; simply run make to compile the project. Then, run the runDecoder.sh script in the Decoders/ folder to perform translations. Running the script with no arguments provides usage info. We only provide trained parameters for Spanish to English to save space, so the sourceLang and targetLang arguments should be set to es and en, respectively.