Debugging the Criminal Justice System
Carleton College Comps Senior Project | 2019-2020


Defining Fairness
In order to develop more fair algorithms, we began by defining what "fair" means in the context of risk assessment algorithms.
Read More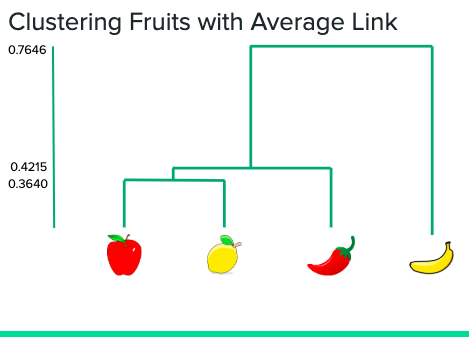
Hierarchical Clustering
Clustering is different from our other algorithms because it is not a binary classifier. Instead of predicting if a person will recidivate, it groups data by similarity as seen above. Our clusters had no correlation to COMPAS score or recidivism.
See the Code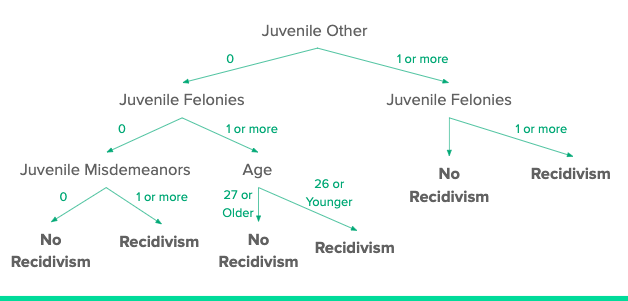
Decision Trees
Above you can see the top levels of our decision tree. Using ID3 or decision achieved the second higest level of accuracy. It also did best a minmizing false positives, suggesting it is the most fair of the algorithms we looked at.
See the Code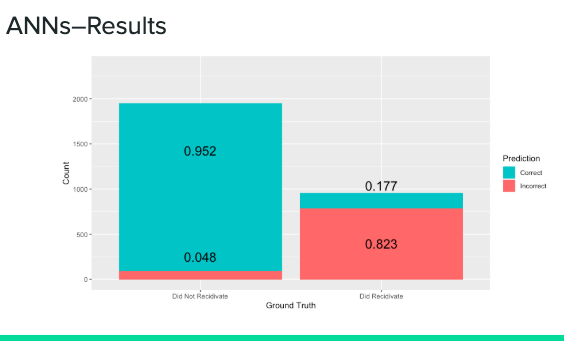
Neural Network
Our Artificial Neural Network (ANN) achieved the highest level of accuracy. However, it was second to decision trees in minimizing false positives.
See the Code
Visit Our GitHub
Visit our GitHub repository to see our data, results, fairness measurements, and more algorithms!
Go to GitHub