Quotes in Context
What is the goal?
We want to quantitatively determine if quotes from athletes or coaches are taken out of their original context. Since context can mean tons of different things, for this project we defined transcripts as the context to quotes found in articles.
What techniques did we use?
We implemented two Natural Language Processing (NLP) techniques to compare articles and transcipts:
Topic Modeling
What is the document talking about?
Sentiment Analysis
How is the document talking about it?
By employing these techniques, we aimed to compare college sport articles to college sport transcripts.
Our analysis includes comparing the two independent pools of articles to interview transcripts to analyze general trends, and after matching articles to transcripts via the quotes in the article, analyzing matched pairs on a case by case basis.
For more info about our project, please visit our paper and/or github linked above!
Results
Overall, as context is a very subjective concept, our results did not concretely answer our guiding questions. We count that is difficult to quantitatively analyze such a qualitative concept such as context. However, we did find that there are language style differences between written articles and spoken transcripts. We also found that sentiment was different between the two corpora on a general level with articles tending to be more negative, and interview transcripts tending to be more generally positive.
General Results
Below is the output of one of our topic modeling runs. Even though the quotes (

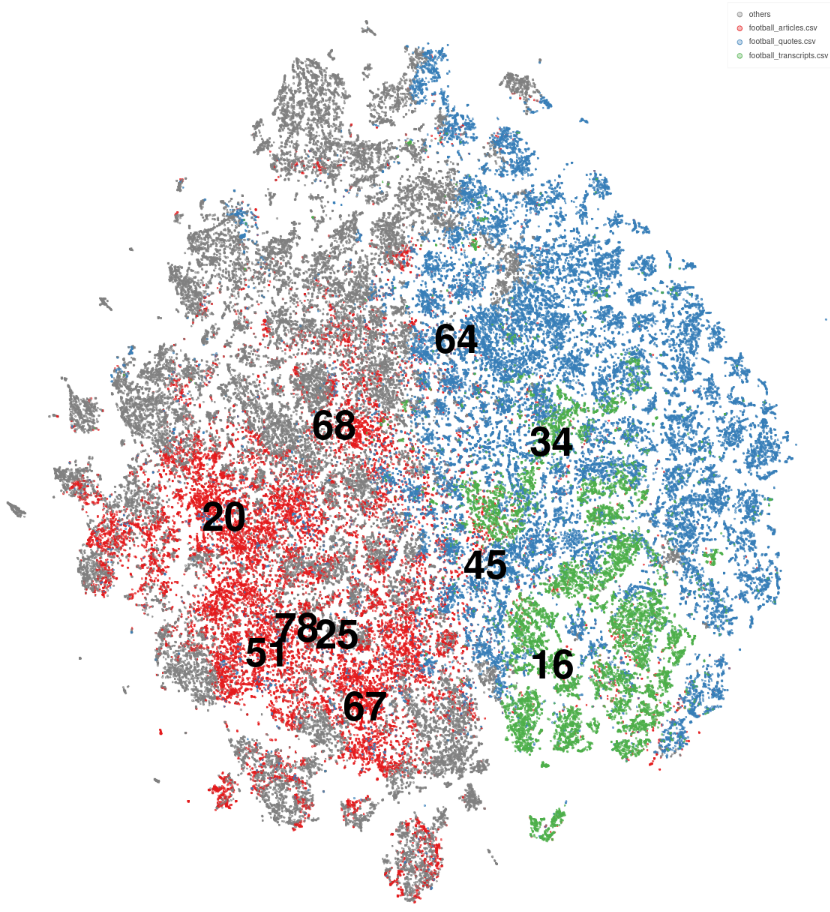
Football Results
Below is the output of one of our topic modeling runs only using football data and removing conversational language. Less documents are being considered different!
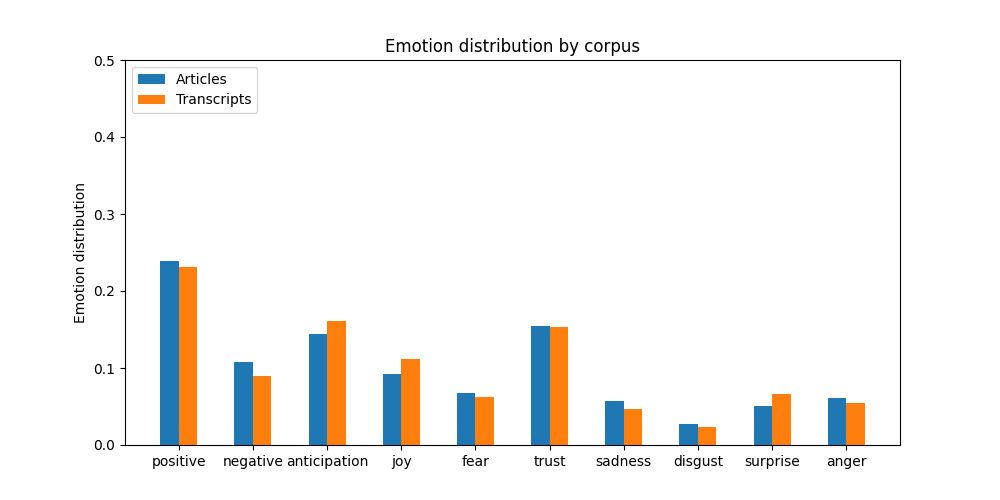
Sentiment Analysis
Below is a picture comparing our general findings from sentiment analysis. While articles have a higher percentage of both general positivity and negativity, when we look at the percentage of individual emotions, we see that articles have higher percentages of negative emotions and lower percentages of positive emotions.
Qualitative Comparison
Below is a qualitative comparison of an article and the transcript it quotes. This pair was chosen because it had the highest euclidean distance between the article's topic vector and the transcript's vector from the LDA output. By reading these, we see that the article uses far more negative language than the transcript. One specific instance of this is highlighted in orange below, the use of the quote "everything that could go wrong in the first three quarters pretty much did." While the coach uses it as a preface to say they had a huge comeback, the article uses it to highlight the low attendance during crunch time of the game.

Quotes in Context Team






A massive thank you to everyone who helped us along the way:
Eric Alexander (our amazing advisor!)
Sarah Calhoun
Mike Tie
Kevin Draper
Michael Cupo